Fediverse
33072 readers
115 users here now
A community to talk about the Fediverse and all it's related services using ActivityPub (Mastodon, Lemmy, KBin, etc).
If you wanted to get help with moderating your own community then head over to [email protected]!
Rules
- Posts must be on topic.
- Be respectful of others.
- Cite the sources used for graphs and other statistics.
- Follow the general Lemmy.world rules.
Learn more at these websites: Join The Fediverse Wiki, Fediverse.info, Wikipedia Page, The Federation Info (Stats), FediDB (Stats), Sub Rehab (Reddit Migration)
founded 2 years ago
MODERATORS
1
2
3
4
5
6
7
8
9
This is a followup to my introduction of BlogOnLemmy, a simple blog frontend. If you haven't seen it, no need because I will be explaining how it works and how you can run your own BlogOnLemmy for free.
Leveraging the Federation
Having a platform to connect your content to likeminded people is invaluable. The Fediverse achieves this in a platform agnostic way, so in theory it shouldn't matter which platform we use. But platform have different userbases that interact with posts in different ways. I've always preferred the forum variety, where communities form and discussion is encouraged.
My posts are shared as original content on Lemmy, and that's who it's meant for. Choosing for a traditional blog style to make a more palatable platform for a wider audience, and in this way also promoting Lemmy.
Constraints
Starting off I did not want the upkeep of another federated instance. Not every new thing that is deployed on the Fediverse needs to stand on its own or made from the ground up as an ActivityPub compatible service. But rather use existing infrastructure, already federated, already primed for interconnectivity. Taking it one step further is not a having a back-end at all, a 'dumb' website as it were. Posts are made, edited, and cross-posted on Lemmy.
The world of CSS and JavaScript on the other hand - how websites are styled and made feature-rich - is littered with libraries. Being treated like black boxes, often just a few functions are used with the rest clogging up our internet experience. Even jQuery, which is used by over 74% of all websites, is already 23kB in its smallest form. I'm not planning on having the smallest possible footprint*, but rather showing a modern web browser provides an underused toolset of natively supported functionality; something the first webdevs would have given their left kidney for.
Lastly, to improve maintainability and simplicity, one page is enough for a blog. Provided that its content can be altered dynamically.
*See optimization
How it's made
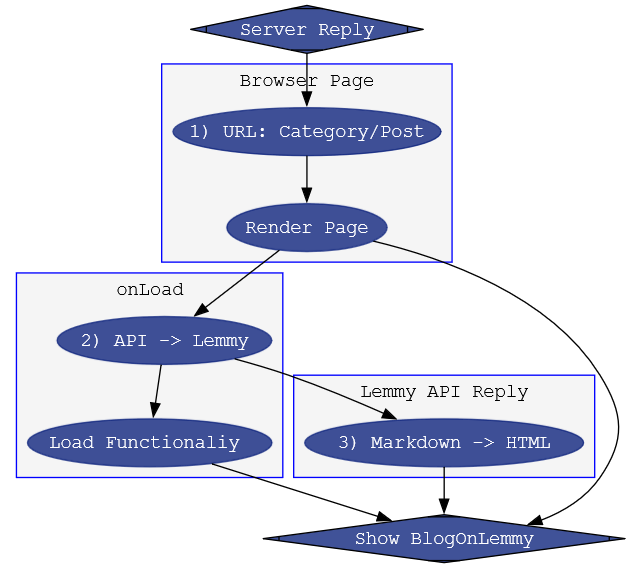
1. URL: Category/post
Even before the browser completely loads the page, we can take a look at the URL. With our constraints only two types of additions are available for us, the anchor and GET parameters. When an anchor, or '#', is present websites scroll to a specific place in a website after loading. We can hijack this behavior and use it to load predefined categories. Like '#blog' or '#linkdumps'. For posts, '#/post/3139396' looks nicer than '?post=3139396', but anchors are rarely search engine compatible. So I'm extracting the GET parameter to load an individual post.
Running JavaScript before the page has done loading should be swift and easy, like coloring the filters or setting Dark/Light mode, so it doesn't delay the site.
2. API -> Lemmy
A simple 'Fetch' is all that's required. Lemmy's API is extensive already, because it's used by different frontends and apps that make an individual’s experience unique. When selecting a category, we are requesting all the posts made by me in one or more lemmy communities. A post or permalink uses the same post_id as on the Lemmy instance. Pretty straight forward.
3. Markdown -> HTML
When we get a reply from the Lemmy instance, the posts are formatted in Markdown. Just as they are when you submit the post. But our browsers use HTML, a different markup language that is interpretable by our browsers. This is where the only code that's not written by me steps in, a Markdown to HTML layer called snarkdown. It's very efficient and probably the smallest footprint possible for what it is, around 1kB.
Optimization
When my blog was launched, I was using a Cloudflare proxy, for no-hassle https handling, caching and CDN. Within the EU, I'm aiming for sub-100ms* to be faster than the blink of an eye. With a free tier of Cloudflare we can expect a variance between 150 and 600ms at best, but intercontinental caching can take seconds.
Nginx and OpenLiteSpeed are regarded as the fastest webservers out there, I often use Apache for testing but for deployment I prefer Nginx's speed and reliability. I could sidetrack here and write another 1000 words about the optimization of static content and TLS handling in Nginx, but that's a story for another time.
* For the website, API calls are made asynchronously while the page is loaded and are not counted
Mythical 14kB, or less?
All data being transferred on the internet is split up into manageable chunks or frames. Their size or Maximum Transmission Unit, is defined by IEEE 802.3-2022 1.4.207 with a maximum of 1518 bytes*. They usually carry 1460 bytes of actual application data, or Maximum Segment Size.
Followed by most server operating systems, RFC 6928 proposes 10x MSS (= Congestion Window) for the first reply. In other words, the server 'tests' your network by sending 10 frames at once. If your device acknowledges each frame, the server knows to double the Congestion Window every subsequent reply until some are dropped. This is called TCP Slow Start, defined in RFC 5681.
10 frames of 1460 bytes contain 14.6kB of usable data. Or at least, it used to. The modern web changed with the use of encryption. The Initial Congestion Window, in my use case, includes 2 TLS frames and from each frame it takes away an extra 29 bytes. Reducing our window to 11.4kB. If we manage our website to fit within this first Slow Start routine, we avoid an extra round trip in the TCP/IP-protocol. Speeding up the website as much as your latency to the server. Min-maxing TCP Traffic is the name of the game.
* Can vary with MTU settings of your network or interface, but around 1500 (+ 14 bytes for headers) is the widely accepted default

Visualizes two raw web requests, 10.7kB vs 13.3kB with TCP Slow Start
- Above Blue: Request Starts
- Between Green: TLS Handshake
- Inside Red: Initial Congestion Window
Icons
Icons are tricky, because describing pixel positions takes up a considerable amount of data. Instead SVG's are commonplace, creating complex shapes programmatically, and significantly reducing its footprint. Feathericons is a FOSS icon library providing a beautiful SVG rendered solution for my navbar. For the favicon, or website icon, I coded it manually with the same font as the blog itself. But after different browsers took liberties rendering the font and spacing, I converted it to a path traced design. Describing each shape individually and making sure it's rendered the same consistently.
Regular vs. Inline vs Minified
If we sum up the filesizes we're looking at around 50kB of data. Luckily servers compress* our code, and are pretty good at it, leaving only 15kB to be transferred; just above our 11kB threshold. By making the code unreadable for humans using minifying scripts we can reduce the final size even more. Only... the files that make up this blog are split up. Common guidelines recommend doing so to prevent one big file clogging up load times. For us that means splitting up our precious 11kB in multiple round trips, the opposite of our goal. Inline code blocks to the rescue, with the added bonus of the entire site now being compressed into one file making the compression more efficient to end optimization at a neat 10.7kB.
* The Web uses Gzip. A more performant choice today is Brotli, which I compiled for use on my server
In Practice
All good in theory, now let's see the effect in practice. I've deployed the blog 4 times, and each version was measured for total download time from 20 requests. In the first graph we notice the impact of not staying inside the Initial Congestion Window, where only the second scenario is delayed by a second round trip when loading the first page.
Scenario 1. and 3. have separate files, and separate requests are made. Taking priority in displaying the website, or the first file, but neglecting potential useable space inside the init_cwnd. We can tell when comparing the second graph, it ends up almost doubling their respective total load times.
The final version is the only one transferring all the data in one round trip, and is the one deployed on the main site. With total download times as low as 51ms, around 150ms as a soft upper limit, and 85ms average in Europe. Unfortunately, that means worldwide tests show load times of 700ms, so I'll eventually implement a CDN.

- Regular (14,46kB): no minification, separate files
- https://dev3.martijn.sh/ - Inline (13,29kB): no minification, one file
- https://dev1.martijn.sh/ - Regular Minified (10,98kB): but still using separate files
- https://dev2.martijn.sh/ - Inline Minified (10,69kB): one page as small as possible
- https://martijn.sh/
I'll be leaving up dev versions until there's a significant update to the site
Content Delivery Network
Speeds like this can only be achieved when you're close to my server, which is in London. For my Eurobros that means blazing fast response times. For anyone else, cdn.martijn.sh points to Cloudflare's CDN and git.martijn.sh to GitHub's CDN. These services allow us to distribute our blog to servers across the globe, so requesting clients always choose the closest server available.
GitHub Pages
An easy and free way of serving a static webpage. Fork the BlogOnLemmy repository and name it 'GitHub-Username'.github.io. Your website is now available as username.github.io and even supports the use of custom domain names. Mine is served at git.martijn.sh.
While testing its load times worldwide, I got response times as low as 64ms with 250ms on the high end. Not surprisingly they deliver the page slightly faster globally than Cloudflare does, because they're optimizing for static content.
Extra features
- Taking over the Light or Dark mode of the users' device is a courtesy more than anything else. Adding to this, a selectable permanent setting. My way of highlighting the overuse of cookies and localStorage by giving the user the choice to store data of a website that is built from the ground up to not use any.
- A memorable and interactable canvas to give a personal touch to the about me section.
- Collapsed articles with a 'Read More'-Button.
- 'Load More'-Button loads the next 10 posts, so the page is as long as you want it to be
Webmentions
Essential for blogging in current year, Webmentions keep websites up-to-date when links to them are created or edited. Fortunately Lemmy has got us covered, when posts are made the first instance sends a Webmention to the hosters of any links that are mentioned in the post.
To stay within scope I'll be using webmention.io for now, which enables us to get notified when linked somewhere else by adding just a single line of HTML to our code.
Notes
- Enabling HTTP2 or 3 did not speed up load times, in fact with protocol negotiations and TLS they added one more packet to the Initial Congestion Window.
- For now, the apex domain will be pointing directly to my server, but more testing is required in choosing a CDN.
- Editing this site for personal use requires knowledge of HTML and JS for now, but I might create a script to individualize blogs easier.
Edit: GitHub | ./Martijn.sh > Blog
10
11
{kind=link}
{kind=link}
12
13
14
15
16
17
18
19
20
{kind=link}
21
197
Peertube number of Active Users are going up last couple of months
(peertube.fediverse.observer)
22
23
24
25
view more: next ›