Yesterday I got bored and decided to try out my old GPUs with Vulkan. I had an HD 5830, GTX 460 and GTX 770 4Gb laying around so I figured "Why not".
Long story short - Vulkan didn't recognize them, hell, Linux didn't even recognize them. They didn't show up in nvtop, nvidia-smi or anything. I didn't think to check dmesg.
Honestly, I thought the 770 would work; it hasn't been in legacy status that long. It might work with an older Nvidia driver version (I'm on 550 now) but I'm not messing with that stuff just because I'm bored.
So for now the oldest GPUs I can get running are a Ryzen 5700G APU and 1080ti. Both Vega and Pascal came out in early 2017 according to Wikipedia. Those people disappointed that their RX 500 and RX 5000 don't work in Ollama should give Llama.cpp Vulkan a shot. Kobold has a Vulkan option too.
The 5700G works fine alongside Nvidia GPUs in Vulkan. The performance is what you'd expect from an APU, but at least it works. Now I'm tempted to buy a 7600 XT just to see how it does.
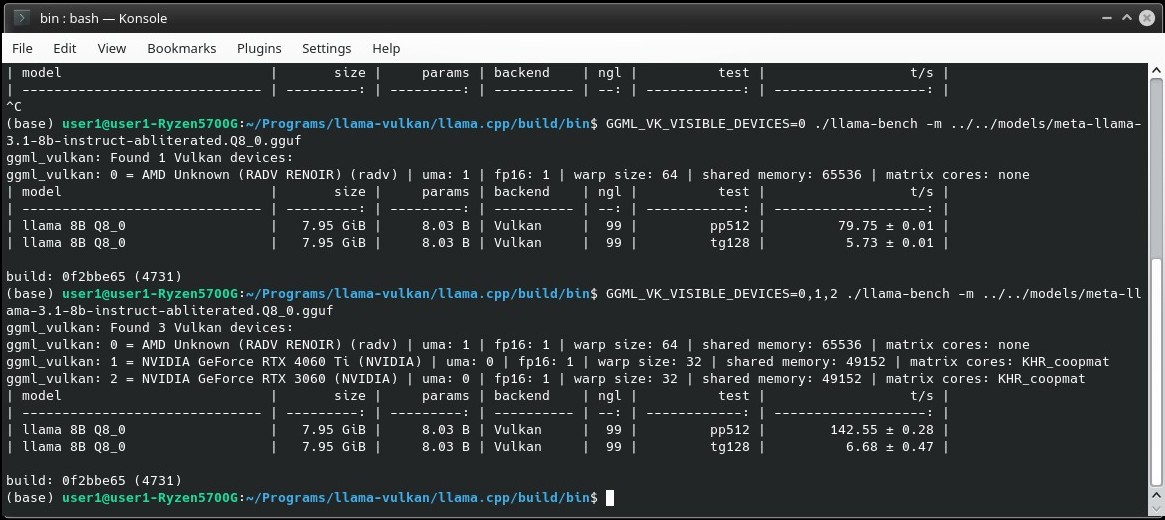
Has anyone else out there tried Vulkan?
I've tried enabling Vulkan on my Intel laptop without a dedicated GPU. But that just makes everything slower.
Did you try running it on the CPU only (BLAS)? Or run it just on the faster and more modern GPUs and see what they do, to compare the numbers to some sort of baseline? Or old GPU only, without more modern ones in the mix? I mean I don't really see the point here. Your computer must be splitting everything up and doing most of the compute somewhere else, if you attach a graphics card with only 1GB of VRAM and the model needs about 8GB. And I'm not sure if the added complexity just makes it slower, or whether it adds something to it. And I'm not sure if I'm missing something or if the output doesn't even show how it gets split up, and what gets executed on which GPU.
There isn't one. I guess I should have made that more clear. Sorry. 🫤
Nope, just a guy with too much time on his hands. I mean, I hope someone out there found it a little informative. There are a lot of people thinking "If Ollama doesn't work then I'm out of luck." I'm just trying to let people know there are other options.
Yes, the Nvidia cards get 30+ t/s together or individually, but the point of this was to see if AMD and Nvidia could work together. Now that this works, I might actually buy an AMD GPU.