For those not aware, nepenthes is an example for the above mentioned approach !
N0x0n
joined 1 year ago
I have also observed this behavior, but only when the file is new and the only seeder is the uploader.
Hower I'm kinda curious to test it out. Any idea if there's some way to script qbittorrent to somehow mimic this behavior?
Download until 99,0% completed with 100% of download speed, then reduce to 0.1% of my download speed until finished?
'It was a very depressing day': Palworld community manager reveals studio's reaction to Nintendo lawsuit
Yeah Lemmy is very Linux oriented :). Though I do agree Linux is harder to get into but that's not because GNU/Linux is difficult, it's because we were so much accustomed to how Windows work !
I don't really remember because it has been ages, but I'm sure my first steps with Windows 98 where awful and not easy and intuitive at all !
Linux has a lot of issues so does Windows (and MacOS) and learning a whole new paradigm of a working system takes time and some investement, but after you get the basic gists, Linux gives you total control of everything ! (Like to see hidden directories is like Windows, just a check box to show hidden files :) don't need a CLI for that)
You rarely need the use of the Terminal when on easier distributions like PopOS or Ubuntu (while I wouldn't suggest the later), However if you tried more difficult distribution first (like arch and derivatives), CLI is mandatory !
Not saying YOU should switch, do whatever makes you happy, more productive and vibes with your current needs/feeling...
However, If you feel the need to switch the Linux community will always welcome you :) Keep in mind, there are good people and a**holes everywhere !
Glad you solved your issue with massgrave, which is a great tool :) ! Have fun with your system !
Edit: Sorry for the off topic XD discussion got a bit heated up haha ! I'm kinda surprised it didn't got deleted !
Oupsii !

cross-posted from: https://lemmy.ml/post/15968883
Hello everyone ! Nobody seems to have an answer on !networking@sh.itjust.works (or maybe they are not interested because it's an enteprise network community?) and !homenetworking@selfhosted.forum seems dead?
Anyway, If anyone could guide me or direct me to the right direction, I would really appreciate it !
TL:DR
What is encapsulated into the frame that makes everyone understand: "OHHH that’s for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Hi everyone !
I'm scratching my head in finding an actual answer on how virtual networking in docker actually works (mostly on the packets/frame level) or some good documentation to improve my understanding on how everything fits together.
Because I'm probably lacking the correct network terminology I made a simple network topology of my network. Don't hesitate to correct any network mistake.
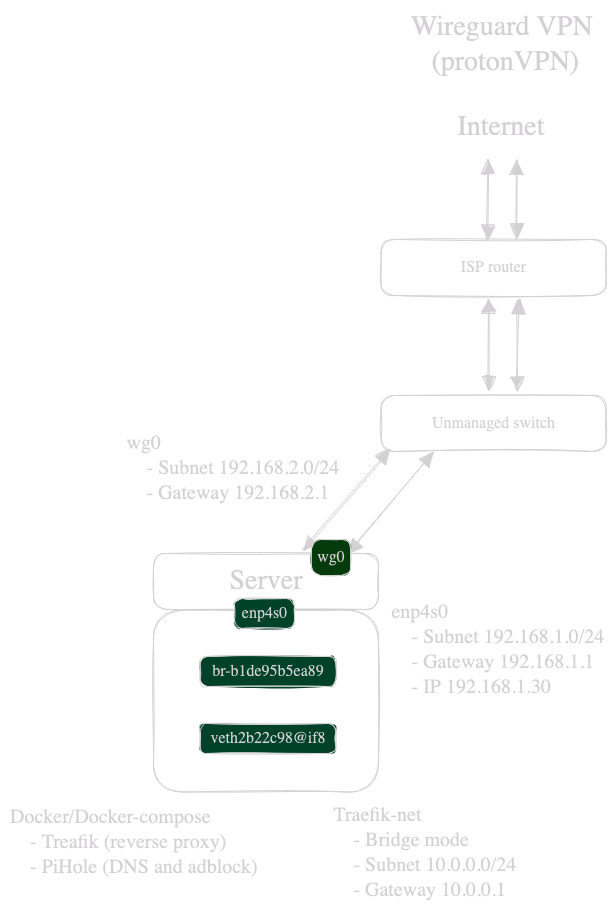
In my scenario, my docker container with the virtual interface veth2b22c98 and the following ip (10.0.0.8) connects to bridge network br-b1de95b5ea89. When I curl, from my conntainer, lemmy.ml the packets/frame is send to my enp4s0 and goes through my wireguard tunnel to my VPN provider which sends back the packet/frame/handshake...
I probed every interface with tcpdump (enp4s0, wg0, br-b1,veth2b):
-
enp4s0: Every packet/frame is encapsulated into the wireguard protocol with my physical interface's IP (192.168.1.30) and no DNS is visible on that interface (like expected) and sends it out to my ISP's public IP.
-
wg0: Shows every packet/frame with the actual protocol with my wireguard's interface IP (192.168.2.1) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
-
br-b1: Shows every packet/frame with the actual protocol with my containers IP (10.0.0.8) with the destination IP of lemmy.ml (Dst: 54.36.178.108)
I know there is a mix of 2 different concepts in my scenario (wireguard tunnel and virtual networking) but I really do not understand how the frame gets back to my docker container. When I look at the frames on wg0, there is no mention of either the MacAddress of my container or the actual IP of my container.
How/when/what ? is exactly happening to my frame so that it gets to the correct target between my physical interface, virtual interface, bridge ? I mean with VLAN's there's a VLAN tag on the frame, so you can easily identify with Wireshark where it should go. But here, I cannot find any clue who or what is doing the magic so the frame finds it's way back to my docker container.
What is encapsulated into the frame that makes everyone understand: "OHHH that's for 10.0.0.8, your docker container on bridge network br-b1de on the veth2b interface !!! "
Sorry for my broken English and lack of networking terminology and thank you for those who beared with me and are willing the give me some hints/proper networking lesson.
view more: next ›
Back in the day, that's what I did ALOT on Windows. Specially because of piracy and my younger me having no idea what he was doing XD !
Still happens on Linux with EndeavourOS but not for the same reasons ! There are millions times more ways to break stuff on Linux but I always learn Something new during the process.
Story time:
Learned the other day that some config files are loaded in a specific order and depending what display manager is installed. That was kinda eye opening to understand cause my system didn't load
.profilewhen.bash_profilewas present and I didn't understood why ! Thanks Archwiki !