Yesterday I got bored and decided to try out my old GPUs with Vulkan. I had an HD 5830, GTX 460 and GTX 770 4Gb laying around so I figured "Why not".
Long story short - Vulkan didn't recognize them, hell, Linux didn't even recognize them. They didn't show up in nvtop, nvidia-smi or anything. I didn't think to check dmesg.
Honestly, I thought the 770 would work; it hasn't been in legacy status that long. It might work with an older Nvidia driver version (I'm on 550 now) but I'm not messing with that stuff just because I'm bored.
So for now the oldest GPUs I can get running are a Ryzen 5700G APU and 1080ti. Both Vega and Pascal came out in early 2017 according to Wikipedia. Those people disappointed that their RX 500 and RX 5000 don't work in Ollama should give Llama.cpp Vulkan a shot. Kobold has a Vulkan option too.
The 5700G works fine alongside Nvidia GPUs in Vulkan. The performance is what you'd expect from an APU, but at least it works. Now I'm tempted to buy a 7600 XT just to see how it does.
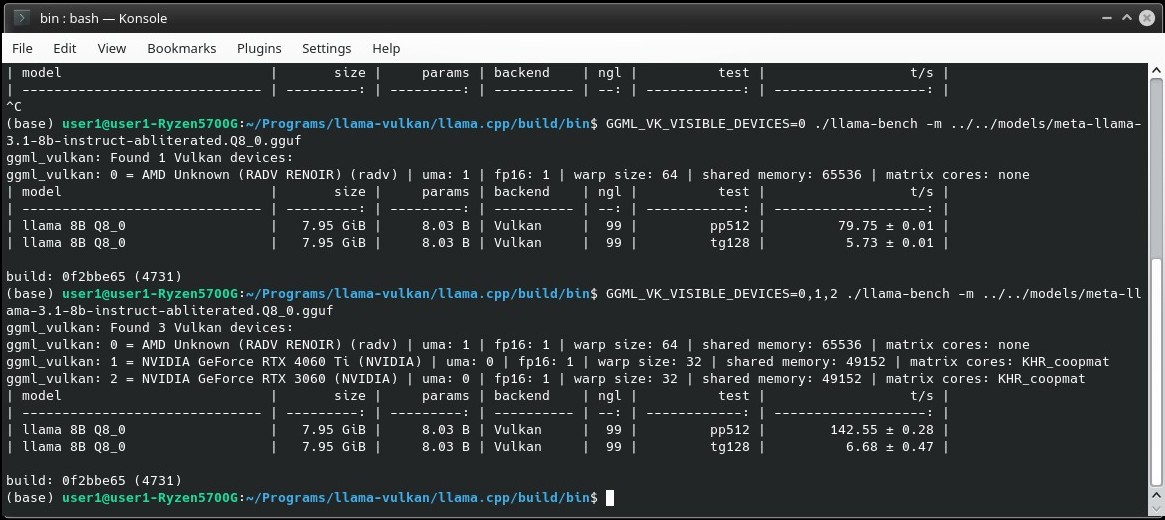
Has anyone else out there tried Vulkan?
Not gonna lie, that sounds beyond my scope. Once I got llama.cpp compiled, everything just worked. I would have no idea how to troubleshoot anything.
I saw a video where someone got the new Indiana Jones running on a Vega 64, so there's really no telling what's possible on AMD hardware. They put so much effort into designing chips, but so little into supporting them.
My laptop (RX 7600s) gets more tokens/sec in Vulkan than in ROCm. I don't know what that's all about.
Here the doc for the record: https://wiki.archlinux.org/title/AMDGPU#Set_module_parameters_in_kernel_command_line
Note, they forgot to add to also blacklist the radeon module.